简介
前文介绍了线程安全的队列和栈,本文继续介绍线程安全的查找结构,实现一个类似线程安全的map结构,但是map基于红黑树实现,假设我们要增加或者删除节点,设计思路是依次要删除或增加节点的父节点,然后修改子节点数据 。尽管这种思路可行,但是难度较大,红黑树节点的插入要修改多个节点的关系。另外加锁的流程也是锁父节点,再锁子节点,尽管在处理子节点时我们已经处理完父节点,可以对父节点解锁,继续对子节点加锁,这种情况锁的粒度也不是很精细,考虑用散列表实现。
散列表
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在存储器存储位置的数据结构。 也就是说,它通过计算出一个键值的函数,将所需查询的数据映射到表中一个位置来让人访问,这加快了查找速度。 这个映射函数称做散列函数,存放记录的数组称做散列表。
举个例子:
假如我们一共有 50 人参加学校的数学竞赛,然后我们为每个学生分配一个编号,依次是 1 到 50.
如果我们想要快速知道编号对应学生的信息,我们就可以用一个数组来存放学生的信息,编号为 1 的放到数组下标为 1 的位置,编号为 2 的放到数组下标为 2 的位置,依次类推。
现在如果我们想知道编号为 20 的学生的信息,我们只需要把数组下标为 20 的元素取出来就可以了,时间复杂度为 O(1),是不是效率非常高呢。
但是这些学生肯定来自不同的年级和班级,为了包含更详细的信息,我们在原来编号前边加上年级和班级的信息,比如 030211 ,03 表示年级,02 表示班级,11 原来的编号,这样我们该怎么存储学生的信息,才能够像原来一样使用下标快速查找学生的信息呢?
思路还是和原来一样,我们通过编号作为下标来储存,但是现在编号多出了年级和班级的信息怎么办呢,我们只需要截取编号的后两位作为数组下标来储存就可以了。
这个过程就是典型的散列思想。其中,参赛学生的编号我们称之为键(key),我们用它来标识一个学生。然后我们通过一个方法(比如上边的截取编号最后两位数字)把编号转变为数组下标,这个方法叫做散列函数(哈希函数),通过散列函数得到的值叫做散列值(哈希值)。
我们自己在设计散列函数的函数时应该遵循什么规则呢?
- 得到的散列值是一个非负整数
- 两个相同的键,通过散列函数计算出的散列值也相同
- 两个不同的键,计算出的散列值不同
虽然我们在设计的时候要求满足以上三条要求,但对于第三点很难保证所有不同的建都被计算出不同的散列值。有可能不同的建会计算出相同的值,这叫做哈希冲突。最常见的一些解决哈希冲突的方式是开放寻址法和链表法,我们这里根据链表法,将散列函数得到相同的值的key放到同一个链表中。
如下图
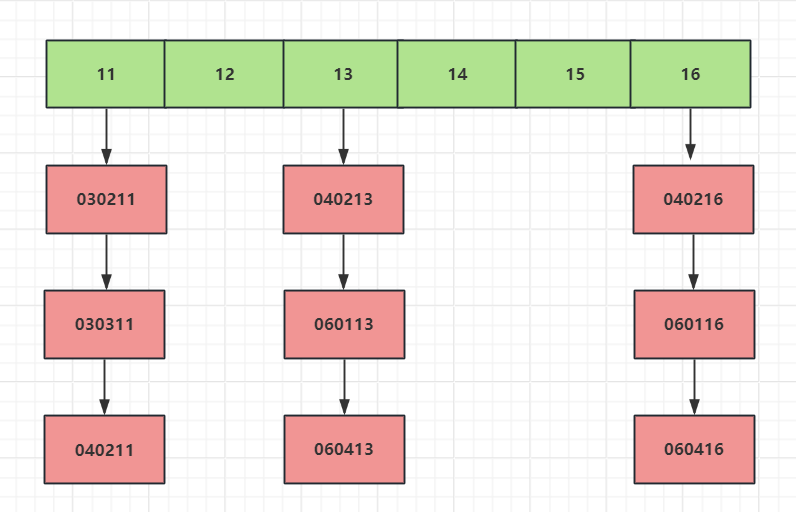
当我们根据key值的后两位计算编号,将编号相同的放入一个链表,比如030211和030311是一个编号,所以将其放入一个链表。
同样的道理040213和060113是一个编号,放入一个链表。
设计思路
我们要实现上述逻辑,可以考虑将11,12,13等hash值放入一个vector中。多线程根据key计算得出hash值的过程并不需要加锁,可以实现并行计算。
但是对于链表的增删改查需要加锁。
所以我们考虑将链表封装为一个类bucket_type,支持数据的增删改查。
我们将整体的查找表封装为threadsafe_lookup_table类,实现散列规则和调度bucket_type类。
代码实现
我们先实现内部的bucket_type类. 为了threadsafe_lookup_table可以访问他,所以将threadsafe_lookup_table设置为其友元类。
class bucket_type{friend class threadsafe_lookup_table;}
我们需要用链表存储键值结构,所以我们可以在bucket_type中添加一个链表存储键值结构。
//存储元素的类型为pair,由key和value构成typedef std::pair<Key, Value> bucket_value;//由链表存储元素构typedef std::list<bucket_value> bucket_data;//链表的迭代器typedef typename bucket_data::iterator bucket_iterator;//链表数据bucket_data data;//改用共享锁mutable std::shared_mutex mutex;
并且添加了互斥量用于控制链表的读写互斥操作,但是我们采用的是共享互斥量,可以实现读写锁,保证读的时候可以并发读。
接下来我们封装一个私有的查找接口,用来内部使用。
//查找key值,找到返回对应的value,未找到则返回默认值bucket_iterator find_entry_for(const Key & key){return std::find_if(data.begin(), data.end(),[&](bucket_value const& item){return item.first == key; });}
然后我们分别实现返回查找的值操作,以及添加操作,并且删除操作
//查找key值,找到返回对应的value,未找到则返回默认值Value value_for(Key const& key, Value const& default_value){std::shared_lock<std::shared_mutex> lock(mutex);bucket_iterator const found_entry = find_entry_for(key);return (found_entry == data.end()) ?default_value : found_entry->second;}//添加key和value,找到则更新,没找到则添加void add_or_update_mapping(Key const& key, Value const& value){std::unique_lock<std::shared_mutex> lock(mutex);bucket_iterator const found_entry = find_entry_for(key);if (found_entry == data.end()){data.push_back(bucket_value(key, value));}else{found_entry->second = value;}}//删除对应的keyvoid remove_mapping(Key const& key){std::unique_lock<std::shared_mutex> lock(mutex);bucket_iterator const found_entry = find_entry_for(key);if (found_entry != data.end()){data.erase(found_entry);}}
这样我们设计完成了bucket_type类。
接下来我们设计threadsafe_lookup_table类。我们用一个vector存储上面的bucket_type类型。 因为我们要计算hash值,key可能是多种类型string, int等,所以我们采用std的hash算法作为散列函数即可.
class threadsafe_lookup_table{private://用vector存储桶类型std::vector<std::unique_ptr<bucket_type>> buckets;//hash<Key> 哈希表 用来根据key生成哈希值Hash hasher;//根据key生成数字,并对桶的大小取余得到下标,根据下标返回对应的桶智能指针bucket_type& get_bucket(Key const& key) const{std::size_t const bucket_index = hasher(key) % buckets.size();return *buckets[bucket_index];}};
get_bucket函数不需要加锁,各个线程可以并行计算哈希值,取出key对应的桶。如果多线程调用同一个bucket的增删改查,就通过bucket内部的互斥解决线程安全问题。
接下来我们完善threadsafe_lookup_table的对外接口
threadsafe_lookup_table(unsigned num_buckets = 19, Hash const& hasher_ = Hash()) :buckets(num_buckets), hasher(hasher_){for (unsigned i = 0; i < num_buckets; ++i){buckets[i].reset(new bucket_type);}}threadsafe_lookup_table(threadsafe_lookup_table const& other) = delete;threadsafe_lookup_table& operator=(threadsafe_lookup_table const& other) = delete;Value value_for(Key const& key,Value const& default_value = Value()){return get_bucket(key).value_for(key, default_value);}void add_or_update_mapping(Key const& key, Value const& value){get_bucket(key).add_or_update_mapping(key, value);}void remove_mapping(Key const& key){get_bucket(key).remove_mapping(key);}
除此之外我们可将当前查找表的副本作为一个map返回
std::map<Key, Value> get_map(){std::vector<std::unique_lock<std::shared_mutex>> locks;for (unsigned i = 0; i < buckets.size(); ++i){locks.push_back(std::unique_lock<std::shared_mutex>(buckets[i]->mutex));}std::map<Key, Value> res;for (unsigned i = 0; i < buckets.size(); ++i){//需用typename告诉编译器bucket_type::bucket_iterator是一个类型,以后再实例化//当然此处可简写成auto it = buckets[i]->data.begin();typename bucket_type::bucket_iterator it = buckets[i]->data.begin();for (;it != buckets[i]->data.end();++it){res.insert(*it);}}return res;}
测试与分析
我们自定义一个类
class MyClass{public:MyClass(int i):_data(i){}friend std::ostream& operator << (std::ostream& os, const MyClass& mc){os << mc._data;return os;}private:int _data;};
接下来我们实现一个函数做测试
void TestThreadSafeHash() {std::set<int> removeSet;threadsafe_lookup_table<int, std::shared_ptr<MyClass>> table;std::thread t1([&]() {for(int i = 0; i < 100; i++){auto class_ptr = std::make_shared<MyClass>(i);table.add_or_update_mapping(i, class_ptr);}});std::thread t2([&]() {for (int i = 0; i < 100; ){auto find_res = table.value_for(i, nullptr);if(find_res){table.remove_mapping(i);removeSet.insert(i);i++;}std::this_thread::sleep_for(std::chrono::milliseconds(10));}});std::thread t3([&]() {for (int i = 100; i < 200; i++){auto class_ptr = std::make_shared<MyClass>(i);table.add_or_update_mapping(i, class_ptr);}});t1.join();t2.join();t3.join();for(auto & i : removeSet){std::cout << "remove data is " << i << std::endl;}auto copy_map = table.get_map();for(auto & i : copy_map){std::cout << "copy data is " << *(i.second) << std::endl;}}
t1用来向map中添加数据(从0到99),t2用来从map中移除数据(从0到99),如果map中未找到则等待10ms继续尝试,t3则继续继续添加数据(从100到199).
然后分别打印插入的集合和获取的map中的数值。
打印可以看到输出插入集合为(0~99),copy的map集合为(100~199).
我们分析一下上述查找表的优劣
1 首先我们的查找表可以支持并发读,并发写,并发读的时候不会阻塞其他线程。但是并发写的时候会卡住其他线程。基本的并发读写没有问题。
2 但是对于bucket_type中链表的操作加锁精度并不精细,因为我们采用的是std提供的list容器,所以增删改查等操作都要加同一把锁,导致锁过于粗糙。
下一节会介绍支持并发读写的自定义链表,可以解决bucket_type中的list锁精度不够的短板。
总结
本文介绍了线程安全情况下栈和队列的实现方式
源码链接:
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day15-threadsafehash
视频链接
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290

