不可定义为虚函数的函数
类的静态函数和构造函数不可以定义为虚函数:
静态函数的目的是通过类名+函数名访问类的static变量,或者通过对象调用staic函数实现对static成员变量的读写,要求内存中只有一份数据。而虚函数在子类中重写,并且通过多态机制实现动态调用,在内存中需要保存不同的重写版本。
构造函数的作用是构造对象,而虚函数的调用是在对象已经构造完成,并且通过调用时动态绑定。动态绑定是因为每个类对象内部都有一个指针,指向虚函数表的首地址。而且虚函数,类的成员函数,static成员函数都不是存储在类对象中,而是在内存中只保留一份。
将析构函数定义为虚函数的作用
类的构造函数不能定义为虚函数,析构函数可以定义为虚函数,这样当我们delete一个指向子类对象的基类指针时可以达到调用子类析构函数的作用,从而动态释放内存。
如下我们先定义一个基类和子类
class VirtualTableA
{
public:
virtual ~VirtualTableA()
{
cout << "Desturct Virtual Table A" << endl;
}
virtual void print()
{
cout << "print virtual table A" << endl;
}
};
class VirtualTableB : public VirtualTableA
{
public:
virtual ~VirtualTableB()
{
cout << "Desturct Virtual Table B" << endl;
}
virtual void print();
};
void VirtualTableB::print()
{
cout << "this is virtual table B" << endl;
}我们写一个函数做测试
void destructVirtualTable()
{
VirtualTableA *pa = new VirtualTableB();
useTable(pa);
delete pa;
}
void useTable(VirtualTableA *pa)
{
//实现动态调用
pa->print();
}程序输出
this is virtual table B
Desturct Virtual Table B
Desturct Virtual Table A在上面的例子中我们先在destructVirtualTable函数中new了一个VirtualTableB类型对象,并用基类VirtualTableA的指针指向了这个对象。
然后将基类指针对象pa传递给useTable函数,这样会根据多态原理调用VirtualTableB的print函数,然后再执行delete pa操作。
此时如果pa的析构函数不写成虚函数,那么就只会调用VirtualTableA的析构函数,不会调用子类VirtualTableB的析构函数,导致内存泄露。
而我们将析构函数写成虚析构之后,可以看到先调用了子类VirtualTableB的析构函数,再调用了基类VirtualTableA的析构函数,达到了释放子类空间的目的。
有人会问?将析构函数不写为虚函数,直接delete子类对象VirtualTableB,调用子类的析构函数不可以吗?比如,如下的调用
VirtualTableB *pb = new VirtualTableB();
delete pa;上述调用没有问题,无论析构函数是否为虚析构都可以成功释放子类空间。但是项目编程中常常会编写一些通用接口,比如上面的useTable函数,
它只接受VirtualTableA类型的指针,所以我们常常会用基类指针接受子类对象来通过多态的方式调用子类函数,为了方便delete基类指针也要释放子类空间,
就要将析构函数设置为虚函数。
虚函数表原理
为了介绍虚函数表原理,我们先实现一个基类和子类
class Baseclass
{
public:
Baseclass() : a(1024) {}
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
int a;
};
// 0 1 2 3 4 5 6 7(虚函数表空间) 8 9 10 11 12 13 14 15(存储的是a)
class DeriveClass : public Baseclass
{
public:
virtual void f() { cout << "Derive::f" << endl; }
virtual void g2() { cout << "Derive::g2" << endl; }
virtual void h3() { cout << "Derive::h3" << endl; }
};一个类对象其内存分布的基本结构为虚函数表地址+非静态成员变量,类的成员函数不占用类对象的空间,他们分布在一片属于类的共有区域。
类的静态成员函数喝成员变量不占用类对象的空间,他们分配在静态区。
虚函数表的地址存储在类对象的起始位置。所以我们利用这个原理,通过寻址的方式访问虚函数表里的函数
void useVirtualTable(){
Baseclass b;
b.a = 1024;
b.f();
void** vtable = *(void ***)(&b);
std::cout << "vtable address is" << vtable << std::endl;
Func pf = (Func)vtable[0];
//b.f()
pf(&b);
pf = (Func)vtable[1];
pf(&b);
pf = (Func)vtable[2];
pf(&b);
std::cout << "size of int is : " << sizeof(int) << std::endl;
std::cout << "size of Baseclass is : " << sizeof(b) << std::endl;
char* objBytes = (char*)&b;
size_t vptrSize = sizeof(void*);
int * aPtr = (int*)(objBytes+vptrSize);
std::cout << "Value of a is : " << *aPtr << std::endl;
}
上面的程序输出
Base::f
vtable address is0x7ff6e72456f0
Base::f
Base::g
Base::h
size of int is : 4
size of Baseclass is : 16
Value of a is : 1024
可以看到b的大小为16字节,因为我的机器是64位的,所以指针类型都占用8字节,int 占用4字节,但是要遵循补齐原则,结构体的大小要为最大成员大小的整数倍,所以要补齐4字节,那么8+4+4 = 16 字节,关于类对象对齐和补齐原则稍后再详述。
b的内存分布如下图
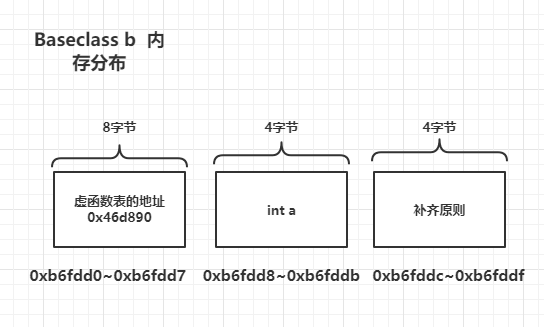
这个根据不同的机器所占的字节数不一样,在32位机器上int为4字节,虚函数表地址为4字节,4+4 = 8字节,这个再之后再说明对齐和补齐的原则。
&b表示取b的地址,因为虚函数表地址存储在b的起始地址,所以&b也是虚函数表的地址的地址,我们通过int* 强转是方便存储b的地址,因为64位机器指针都是8字节,32位机器指针是4字节。
p为虚函数表的地址的地址,p+1具体移动了4个字节,因为p+1移动多少个字节取决于p所指向的数据类型int,int为4字节,所以p+1在p的地址移动四个字节,p+2在p的地址移动8个字节。
p只想虚函数表的地址,换句话说p存储的是虚函数表的地址,虚函数表地址占用8字节,p+2就是从p向后移动8字节,这样刚好找到a的地址。
那么*(p+2)就是取a的数值。int*(*p)就是取虚函数表的地址,转为int*是方便读写。
我们将b的内存分布以及虚函数表结构画出来
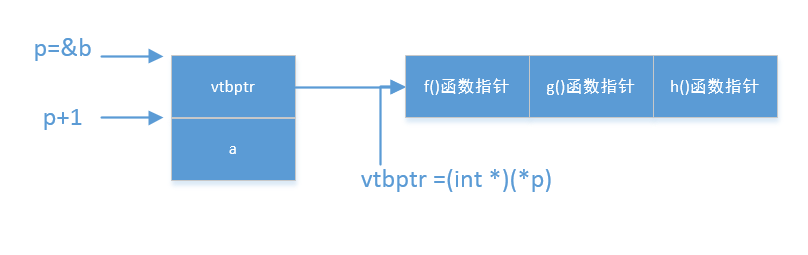
上图中可以看到虚函数表中存储的是虚函数的地址,所以通过不断位移虚函数表的指针就可以达到指向不同虚函数的目的。
Func pFun = (Func)(*(int *)(*p));
pFun();*(int *)(*p)就是取出虚函数表首地址指向的虚函数,再通过Func转化为函数类型,然后调用pFun即可调用虚函数f。
所以想调用第二个虚函数g,将(int*)(*p) 加2 位移8个字节即可
pFun = (Func) * ((int *)(*p) + 2);
pFun();同样的道理调用h就不赘述了。
继承关系中虚函数表结构
DeriveClass继承了BaseTest类,子类如果重写了虚函数,则子类的虚函数表中存储的虚函数为子类重写的,否则为基类的。
我们画一下DeriveClass的虚函数表结构
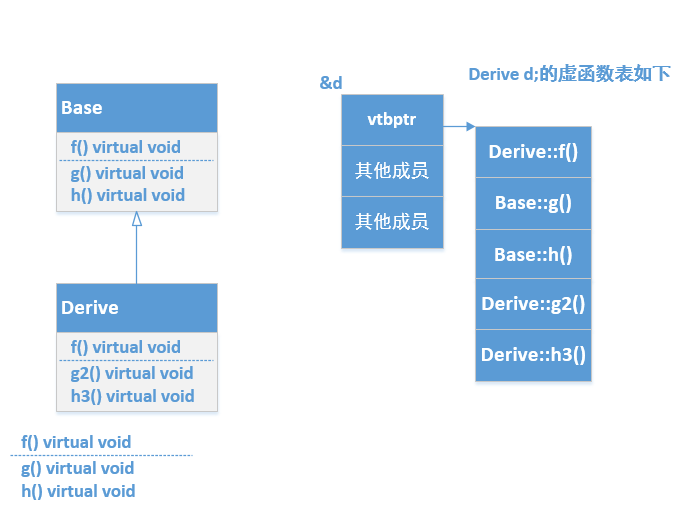
因为函数f被DeriveClass重写,所以DeriveClass的虚函数表存储的是自己重写的f。
而虚函数g和h没有被DeriveClass重写,所以DeriveClass虚函数表存储的是基类的g和h。
另外DeriveClass虚函数表里也存储了自己特有的虚函数g2和h3.
下面我们还是利用寻址的方式调用虚函数
void deriveTable(){
DeriveClass b;
b.a = 1025;
void** vtable = *(void ***)(&b);
std::cout << "vtable address is" << vtable << std::endl;
Func pf = (Func)vtable[0];
//b.f()
pf(&b);
pf = (Func)vtable[1];
pf(&b);
pf = (Func)vtable[2];
pf(&b);
}
程序输出
vtable address is0x7ff6e72456b0
Derive::f
Base::g
Base::h
可见DeriveClass虚函数表里存储的f是DeriveClass的f。(int *)(*p)表述取出p所指向的内存空间的内容,p指向的正好是虚函数表的地址,所以*p就是虚函数表的地址。
因为我们不知道虚函数表的具体类型,所以转为int*类型,因为指针在64位机器上都是8字节,可以保证空间大小正确。
接下来就是寻址和函数调用的过程,这里不再赘述。
多重继承的虚函数表
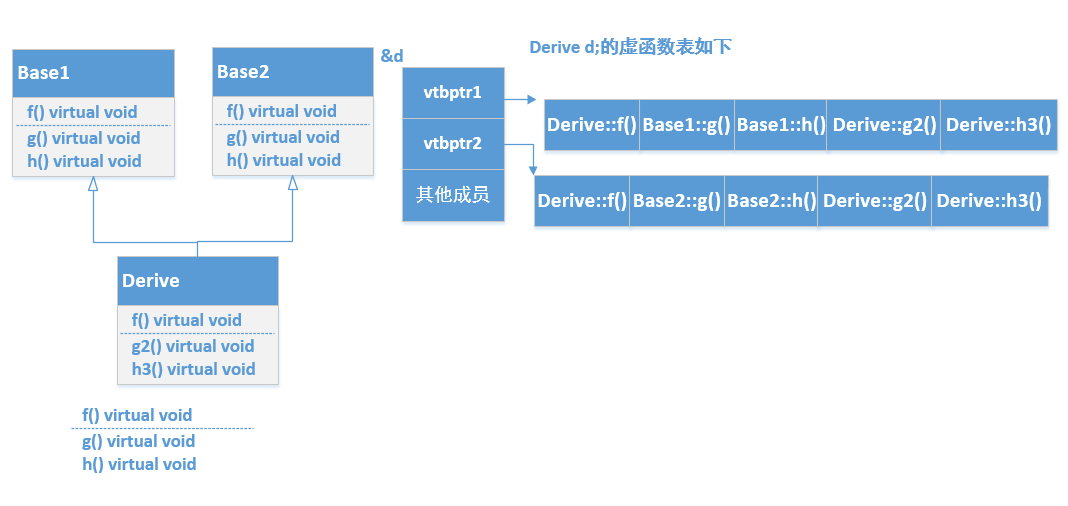
上面的例子我们知道,如果类有虚函数,那么编译器会为该类的实例分配8字节存储虚函数表的地址。
所有继承该类的子类也会拥有8字节的空间存储自己的虚函数表地址。
多重继承的情况就是类对象空间里存储多张虚函数表地址。子类继承于两个基类,并且基类都有虚函数,那么子类就有两张虚函数表。
多态调用原理
当我们通过基类指针存储子类对象时,调用虚函数,会调用子类的实现版本,这叫做多态。
通过前面的实验和图示,我们已经知道如果子类重写了基类的虚函数,那么他自己的虚函数表里存储的就是自己实现的版本。
通过基类指针存储子类对象时,基类指针实际指向的是子类的空间,寻址也是找到子类的虚函数表,从虚函数表中找到子类实现的虚函数,
然后调用子类版本,从而达到多态效果。
对齐和补齐规则
在考察一个类对象所占空间时,虚函数、成员函数(包括静态与非静态)和静态数据成员都是不占用类对象的存储空间的。对象大小= vptr(虚函数表指针,可能不止一个) + 所有非静态数据成员大小 + Aligin字节大小(依赖于不同的编译器对齐和补齐)
对齐:类(结构体)对象每个成员分配内存的起始地址为其所占空间的整数倍。
补齐:类(结构体)对象所占用的总大小为其内部最大成员所占空间的整数倍。
下面我们先定义几个类
namespace AligneTest
{
class A
{
};
class B
{
char ch;
void func()
{
}
};
class C
{
char ch1; //占用1字节
char ch2; //占用1字节
virtual void func()
{
}
};
class D
{
int in;
virtual void func()
{
}
};
class E
{
char m;
int in;
};
}然后通过代码测试他们的大小
extern void aligneTest()
{
AligneTest::A a;
AligneTest::B b;
AligneTest::C c;
AligneTest::D d;
AligneTest::E e;
cout << "sizeof(a): " << sizeof(a) << endl;
cout << "sizeof(b): " << sizeof(b) << endl;
cout << "sizeof(c): " << sizeof(c) << endl;
cout << "sizeof(d): " << sizeof(d) << endl;
cout << "sizeof(e): " << sizeof(e) << endl;
}程序输出
sizeof(a): 1
sizeof(b): 1
sizeof(c): 16
sizeof(d): 16
sizeof(e): 8我们分别对每个类的大小做解释
a 是A的对象,A是一个空类,编译器为了区分不同的空类,所以为每个空类对象分配1字节的空间保存其信息,用来区别不同类对象。
b 是B的对象,因为B中定义了一个char成员变量和func函数,func函数不占用空间,所以b的大小为char的大小,也就是1字节。
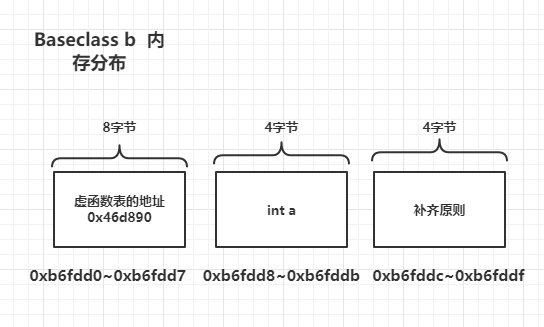
c 是C的对象,因为C中包含虚函数,所以C的对象c中会分配8字节用来存储虚函数表,虚函数表放在c内存的首地址,然后是ch1,
以及ch2。假设c的起始地址为0,那么0~7字节存储虚函数表地址,第8个字节是1的整数倍,所以不同对齐,第8个字节存储ch1。
第9个字节是1的整数倍,所以第9个字节存储ch2。那么c的大小为8 + 2 = 10, 因为补齐规则要求c的大小为最大成员大小的整数
倍,最大成员为虚函数表地址8字节,所以要补齐6个字节,10+6 = 16,所以c的大小为16字节。
其内存分配如下图
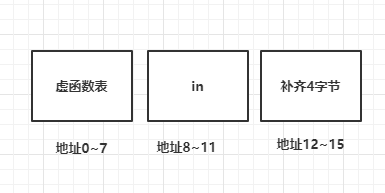
d 是D的对象,因为D中包含虚函数,所以D的对象d中会分配8字节空间存储虚函数表地址,比如0~7字节存储虚函数表地址,接下来第8个字节,
因为int为4字节,8是4的整数倍,所以不需要对齐,第8~11字节存储in,这样d的大小变为8+4= 12, 因为根据补齐规则需要补齐4字节,总共
大小为16字节刚好是最大成员大小8字节的整数倍。所以d为16字节
其内存分配图如下
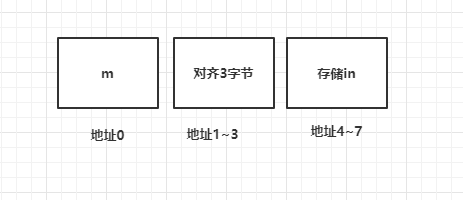
e 是E的对象,e会为m分配1字节空间,为in分配4字节空间,假设地址0存储m,接下来地址1存储in。
因为对齐规则要求类(结构体)对象每个成员分配内存的起始地址为其所占空间的整数倍,1不是4的整数倍,所以要对齐。
对齐的规则就是地址后移找到起始地址为4的整数倍,所以要移动3个字节,在地址为4的位置存储in。
那么e所占的空间就是 1(m占用) + 3(对齐规则) + 4(in占用) = 8 字节。
如下图所示
为什么要有对齐和补齐
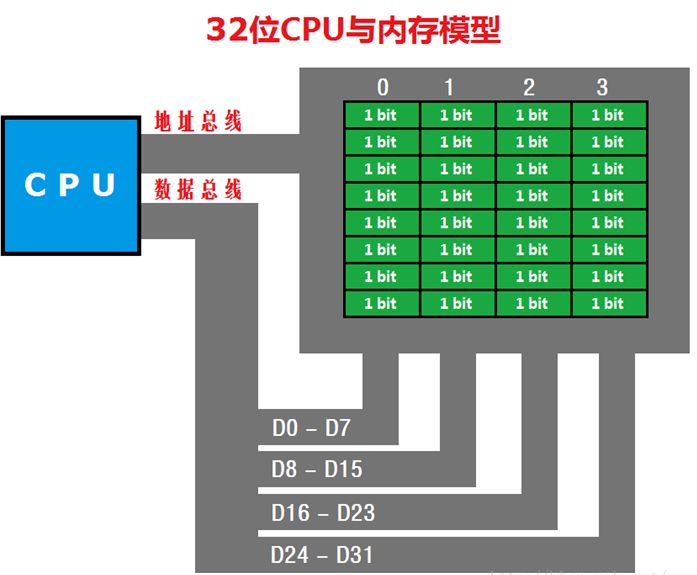
这个要从计算机CPU存取指令说起,
上图为32位机器内存模型,CPU通过地址总线和数据总线寻址读写数据。如果是64位机器,就是8列。
通过对齐和补齐规则,可以一次读取内存中的数据,不需要切割和重组,是典型的用空间换取时间的策略。
比如有如下类
class Test{
int m;
char b;
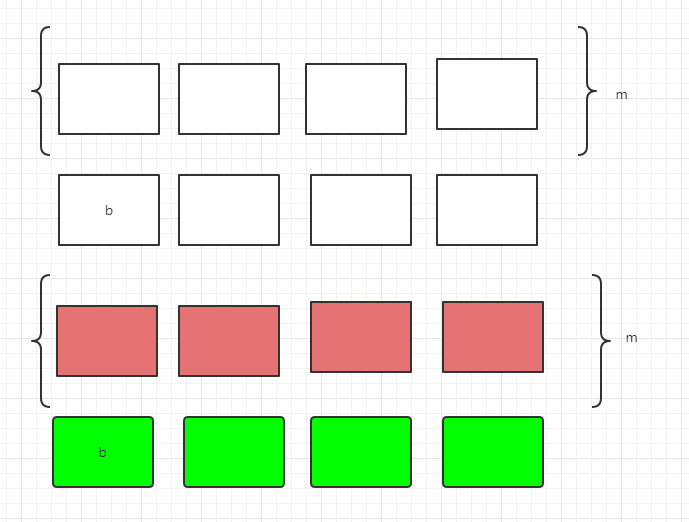
}我们用Test生成了两个对象t1和t2,他们在内存中存储如下,无色的表示t1的内存存储,彩色的表示t2。
在不采用对齐和补齐策略的情况下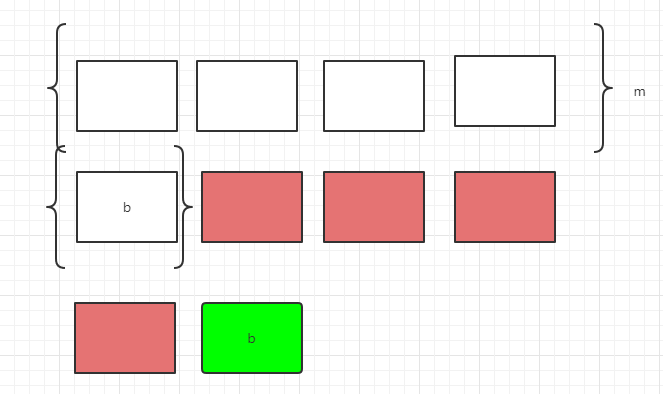
在采用对齐和补齐策略的情况下
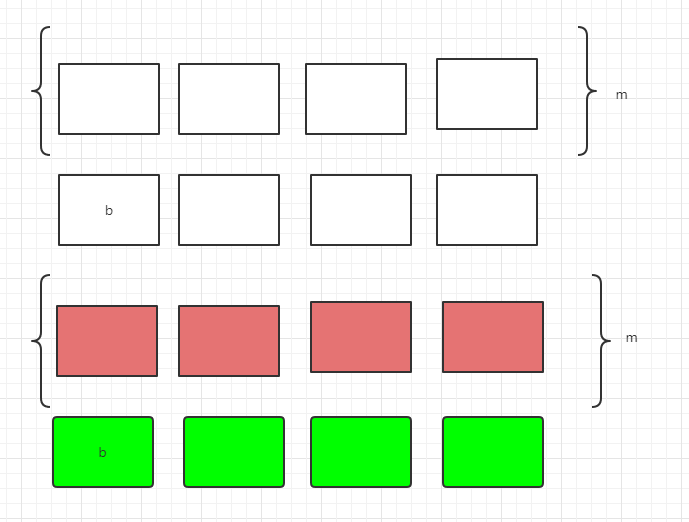
可见不采用对齐和补齐策略,节省空间,但是要取三次能取完数据,取出后还要切割和拼接,最后才能使用。
采用对齐和补齐策略,牺牲了空间换取时间,读取四次,但是不需要切割直接可以使用。
对于64位机器,采用对齐和补齐策略,只需读取两次,每次取出的都是Test对象,效率非常高。
资源链接
本文模拟实现了vector的功能。
视频链接https://www.bilibili.com/video/BV1JT411j7HP/?vd_source=8be9e83424c2ed2c9b2a3ed1d01385e9
源码链接 https://gitee.com/secondtonone1/cpplearn



{kind=link}
{kind=link}
{kind=link}